latex
基本格式
\documentclass{article}
\usepackage[UTF8]{ctex}
\title{XIDIAN UNIVERSITY} %———总标题
\author{YanTaTaiBai}
%这里是导言区
\begin{document}
% —— 显示标题
\maketitle
%—— 制作目录(目录是根据标题自动生成的)
\tableofcontents
%——一号子标题
\section{China}
%——二号子标题
\subsection{Shannxi}
%——三号子标题
\subsubsection{Xian}
%{}中的内容加粗显示
\paragraph{XIDIAN UNIVERSITY}is a famous university.
\subparagraph{School of telecommunication engineering} is in the best institute of XDU.
\subsection{State Key Laboratory of ISN }
\paragraph{XiDian University} is the best university in communications industry.
Hello, world!
\end{document}
排版
%分段
This paper.\par
%首行不缩进
\noindentIn late June, the TUG 2010 conference was held in San Francisco to great success.
%换行
\\
%调整页边距
\usepackage{geometry}
\geometry{a4paper,scale=0.8}
%文字加粗
\textbf{文本}
%文字下划线
\underline{文本}
%文字颜色
\usepackage{xcolor}
\textcolor{<color>}{<text>}
{\color{red} highlighted}
%行号
%switch 双栏
%left Line numbers in left margin (default)
%pagewise Restart numbering on every page
\usepackage[switch, pagewise]{lineno}
\linenumbers
%文字删除线
\usepackage{ulem}
\sout{文字} %删除线
\uwave{文字} %波浪线
\xout{文字} %斜删除线
\uuline{文字} %双下划线
添加图片
\documentclass{article}
\usepackage{graphicx}
\begin{document}
\includegraphics{a.jpg}
\end{document}
%修改图片大小缩放80%
\includegraphics[width = .8\textwidth, height=6cm]{a.jpg}
%crap image
\usepackage{graphicx}
...
\begin{figure}[htbp]
\begin{center}
\includegraphics[trim=left bottom right top, clip]{file}
\caption{default}
\label{default}
\end{center}
\end{figure}
%图片说明
\begin{figure}[!ht]
\centering
\includegraphics[]{ch1_architechture.png}
\caption{Architechture du système Android}
\label{图片的引用标签}
\end{figure}
h 当前位置。将图形放置在正文文本中给出该图形环境的地方。如果本页所剩的页面不够,这一参数将不起作用。
t 顶部。将图形放置在页面的顶部。
b 底部。将图形放置在页面的底部。
p 浮动页。将图形放置在一只允许有浮动对象的页面上。
htb 一般使用
!h 试图放在当前位置
ht
%并排图片
\usepackage{graphicx}
\usepackage{subfigure}
\begin{figure}[htbp]
\centering
\subfigure[name of the subfigure]{
\begin{minipage}{8cm}
\centering
\includegraphics[width = .9\textwidth]{images/hidden_rmse.eps}
\end{minipage}
}
\subfigure[name of the subfigure]{
\begin{minipage}{8cm}
\centering
\includegraphics[width = .9\textwidth]{images/nin_rmse.eps}
\end{minipage}
}
\caption{name of the figure}
\label{fig:1}
\end{figure}
数学公式
%行内公式
$公式$
%行间公式
$$行间公司$$
%中间元素结合成一个整体
{}
%省略号
\dots
%垂直省略号
\vdots
%强调
\hat{a}
\bar{a}
\dot{a}
\tilde{a} %波浪线
%点乘
\cdot
%原点乘
\odot
%无穷
\infty
%极限
%lim
\lim
\lim_{x \to 2} f(x) = 5
%除
\div
%叉乘
\times
%向量
\overrightarrow{AB}
占位或对齐
&
公式组合
\begin{equation*} %带*无编号
\end{equation*}
极小值
\min
绝对值
\left| \frac{a}{b} \right|
二范数
\left\|Q\right\|
数学公式空格
a \qquad b
a \ b
公式引用
\ begin{equation}
I_{t}=I_{0}+\sum_{i=1}^{t}(Q_{i}-d_{i})\label{con:inventoryflow}
\ end{equation}
Equation \ ref{con:inventoryflow} is the inventory flow formula.
实数集
\usepackage{amssymb}
\mathbb{R}
花体
\mathcal{L}
空心
\mathbb{R}
黑体
\mathbf{R}
罗马字体
\mathrm{R}
无衬线体
\mathsf{R}
书法体
\mathcal{R}
手写体
\mathscr{R}
数学字体加粗
\usepackage{bm}
\bm{R}
撇号
a'
角度
90^\circ
exp
\exp
删除公式效果
\usepackage{cancel}
\xcancel{公式内容}
希腊字母

数学符号
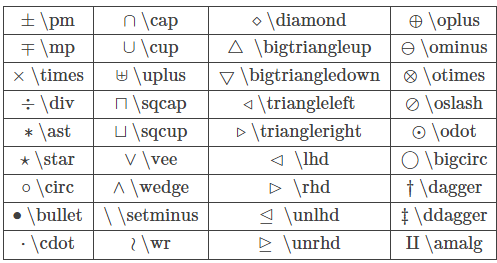
关系运算符
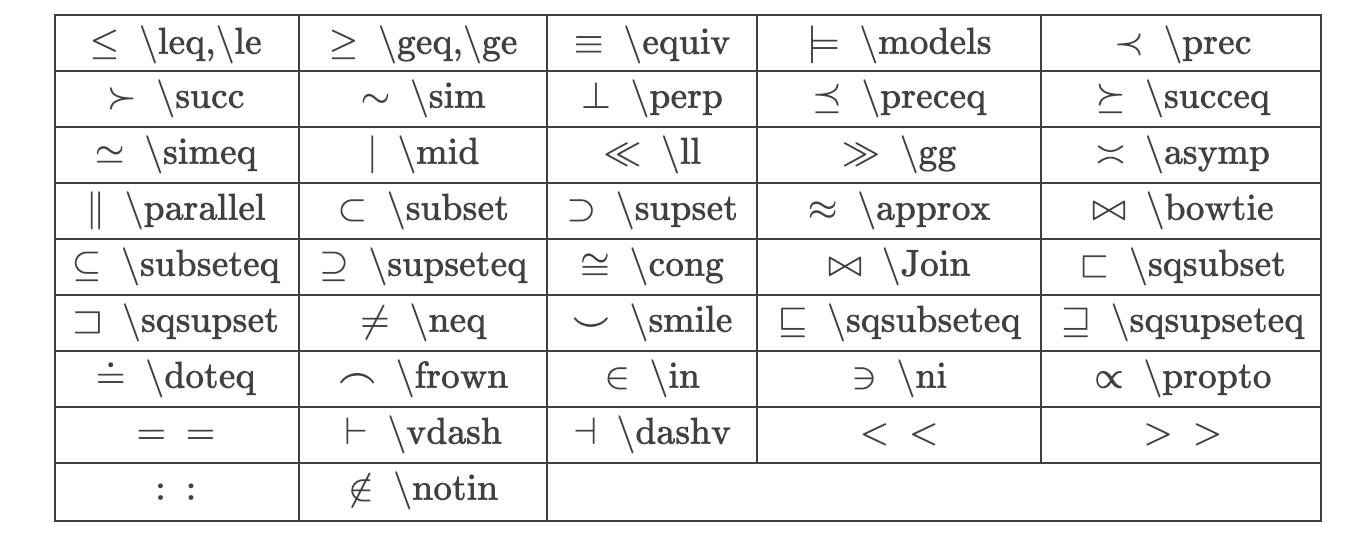
括号
% 大括号(加转义)
\{\}
分数 $\frac{a-1}{2}$
\frac{a-1}{2}
根号 $\sqrt{a+b}$
\sqrt{a+b}
导数
求导
$\mathrm{d}$
偏导
$\partial$
上标^ $a^3$
a^3
下标_ $a_1$
a_1
累加 $\sum_{i=1}^{10}$
\sum_{i=1}^{10}
积分 $\int_{0}^{\frac{\pi}{2}}$
\int_{0}^{\frac{\pi}{2}}
累乘 $\prod_\epsilon$
\prod_\epsilon
矩阵转置 $A^{\mathrm{T}}$
%mathrm 指罗马字体
$A^{\mathrm{T}}$
极限 $\lim_{x \to 2} f(x) = 5$
\lim_{x \to 2} f(x) = 5
多行公式堆积(nonumber 代表没有公式编号)
% & 指定位置对齐
\begin{align}
x &= t + \cos{t} + 1 \\
y &= 2\sin{t} \nonumber
\end{align}
大括号
f(x)=\left\{
\begin{aligned}
x & = & \cos(t) \\
y & = & \sin(t) \\
z & = & \frac xy
\end{aligned}
\right.
矩阵 \(\begin{matrix} x&y\\z&v \end{matrix}\) \(\begin{vmatrix} x&y\\z&v \end{vmatrix}\) \(\begin{bmatrix} x&y\\z&v \end{bmatrix}\) \(\begin{pmatrix} x&y\\z&v \end{pmatrix}\)
\begin{matrix} x&y\\z&v \end{matrix}
\begin{vmatrix} x&y\\z&v \end{vmatrix}
\begin{bmatrix} x&y\\z&v \end{bmatrix}
\begin{pmatrix} x&y\\z&v \end{pmatrix}
编号
%不带序号
\begin{itemize}
\item[-] good morning...
\item[-] good morning....
\end{itemize}
%带序号[1]序号为1,[step i]序号为i,[(1)]序号为(1)(2)...
\usepackage{enumerate}
\begin{enumerate}[step 1]
\item good morning...
\item good morning....
\end{enumerate}
%数序公式手动编号
\eqno{(1)}
$$x^n+y^n=z^n \eqno{(1)}$$
算法
\usepackage{algorithm}
\usepackage{algpseudocode}
\usepackage{amsmath}
% Use Input in the format of Algorithm
\renewcommand{\algorithmicrequire}{\textbf{Input:}}
% Use Output in the format of Algorithm
\renewcommand{\algorithmicensure}{\textbf{Output:}}
% 函数
\Function{function name}{var1, var2}
\EndFunction
%Input
\Require
%Output
\Ensure
% 调整大小
\begin{minipage}{0.9\linewidth}
\renewcommand{\algorithmicrequire}{\textbf{Input:}}
\renewcommand{\algorithmicensure}{\textbf{Output:}}
\begin{algorithm}[H]
\caption{Training process of Transvae}
\label{training-process}
\begin{algorithmic}[1]
\Require
Water quality sequences: ${X}{=}\{x_{1},\dots,x_{T}\}$
\Ensure
Predicted sequences: $\hat{Y}$
\For{each epoch}
\State Generate $\mathcal{X}$ \textit{via} local and global embedding in (\ref{eq:local_embedding}, \ref{eq:global_embedding})
\State Generate $H$ \textit{via} multi-head self-attention mechanism in (\ref{eq:attention_qkv}) with $\mathcal{X}$
\State Generate $\bar{H}$ \textit{via} Feed-forward and Residual Network in (\ref{eq:feed-forward})
\State Generate mean $\mu_{z_t}$ and co-variance $\Sigma_{z_t}$ \textit{via} two linear models
\State Generate randomly sampled $z$ from the $q_{\phi}(z_t|\tilde{h}_t)$
\State Generate final reconstruction $\hat{X}$ \textit{via} in (\ref{eq:reconstructed})
\State Compute loss $\mathcal{L}$ with (\ref{con:loss_fn})
\State Generate $\hat{Y}$ \textit{via} present anomaly score with reconstructed $\hat{X}$ in (\ref{eq:anomaly-score})
\State Apply BPTT to backpropagate gradient
\State Train the model for minimizing the loss with the Adam optimizer
\EndFor
\end{algorithmic}
\end{algorithm}
\end{minipage}
自定义 Initialize
\algnewcommand{\Initialize}[1]{
\State \textbf{Initialize:}
\Statex \hspace*{\algorithmicindent}\parbox[t]{.8\linewidth}{\raggedright #1}
}
% 单纯引用
\begin{algorithm}[htb]
\caption{ Framework of ensemble learning for our system.}
\label{alg:Framwork}
\begin{algorithmic}[1]
\Require
The set of positive samples for current batch, $P_n$;
The set of unlabelled samples for current batch, $U_n$;
Ensemble of classifiers on former batches, $E_{n-1}$;
\Ensure
Ensemble of classifiers on the current batch, $E_n$;
\State Extracting the set of reliable negative and/or positive samples $T_n$ from $U_n$ with help of $P_n$;
\label{code:fram:extract}
\State Deleting some weak classifiers in $E_n$ so as to keep the capacity of $E_n$;
\label{code:fram:select} \\
\Return $E_n$;
\end{algorithmic}
\end{algorithm}
函数循环
% 循环
\begin{algorithm}[h]
\caption{An example for format For \& While Loop in Algorithm}
\begin{algorithmic}[1]
\For{each $i\in [1,9]$}
\State initialize a tree $T_{i}$ with only a leaf (the root);
\State $T=T\cup T_{i};$
\EndFor
\ForAll {$c$ such that $c\in RecentMBatch(E_{n-1})$}
\label{code:TrainBase:getc}
\State $T=T\cup PosSample(c)$;
\label{code:TrainBase:pos}
\EndFor;
\For{$i=1$; $i<n$; $i++$ }
\State $//$ Your source here;
\EndFor
\For{$i=1$ to $n$}
\State $//$ Your source here;
\EndFor
\State $//$ Reusing recent base classifiers.
\label{code:recentStart}
\While {$(|E_n| \leq L_1 )and( D \neq \phi)$}
\State Selecting the most recent classifier $c_i$ from $D$;
\State $D=D-c_i$;
\State $E_n=E_n+c_i$;
\EndWhile
\label{code:recentEnd}
\end{algorithmic}
\end{algorithm}
% 判断
\begin{algorithm}
\caption{My algorithm}\label{euclid}
\begin{algorithmic}[1]
\Procedure{MyProcedure}{}
\State $\textit{stringlen} \gets \text{length of }\textit{string}$
\State $i \gets \textit{patlen}$
\BState \emph{top}:
\If {$i > \textit{stringlen}$} \Return false
\EndIf
\State $j \gets \textit{patlen}$
\BState \emph{loop}:
\If {$\textit{string}(i) = \textit{path}(j)$}
\State $j \gets j-1$.
\State $i \gets i-1$.
\State \textbf{goto} \emph{loop}.
\State \textbf{close};
\EndIf
\EndProcedure
\end{algorithmic}
\end{algorithm}
代码
\usepackage{fancyvrb}
\usepackage{xcolor}
\begin{Verbatim}[numbers=left, frame=single, formatcom=\color{black}]
#include <iostream>
int main() {
std::cout << "Hello, world!" << std::endl;
return 0;
}
\end{Verbatim}
引用
%添加文件mybibtex.bib
% bib文件内容
@article{name1,
author = {作者, 多个作者用 and 连接},
title = {标题},
journal = {期刊名},
volume = {卷20},
number = {页码},
year = {年份},
abstract = {摘要, 这个主要是引用的时候自己参考的, 这一行不是必须的}
}
@book{name2,
author ="作者",
year="年份2008",
title="书名",
publisher ="出版社名称"
}
%设置引用文献的类型
\bibliographystyle{plain}
%引用
\cite{引用文章名称}
%生成参考文献列表
\bibliography{mybibfile.bib}
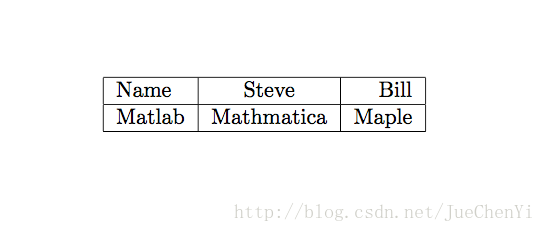
表格
\documentclass{article}
\begin{document}
\begin{table}
\begin{tabular}{|l|c|r|} %l(left)居左显示 r(right)居右显示 c居中显示
\hline
Name&Steve&Bill\\
\hline
Matlab&Mathmatica&Maple\\
\hline
\end{tabular}
\label{Tab:Tcr}
\end{table}
\end{document}
调整表格大小
\begin{table}
\caption{表格标题}
\scalebox{0.9}{
\begin{tabular}
……
\end{tabular}}
\end{table}
三线表
\documentclass[UTF8]{ctexart}
\begin{document}
\begin{table}
\begin{tabular}{ccc}
\hline
姓名& 学号& 性别\\
\hline
Steve Jobs& 001& Male\\
Bill Gates& 002& Female\\
\hline
\end{tabular}
\end{table}
\end{document}

加载 booktabs 宏包之后可以使用 \toprule 和 \bottomrule 命令分别画出表格头和表格底的粗横线,而用 \midrule 画出表格中的横线。
\documentclass[UTF8]{ctexart}
\usepackage{booktabs} %需要加载宏包{booktabs}
\begin{document}
\begin{table}
\begin{tabular}{ccc}
\toprule %添加表格头部粗线
姓名& 学号& 性别\\
\midrule %添加表格中横线
Steve Jobs& 001& Male\\
Bill Gates& 002& Female\\
\bottomrule %添加表格底部粗线
\end{tabular}
\end{table}
\end{document}
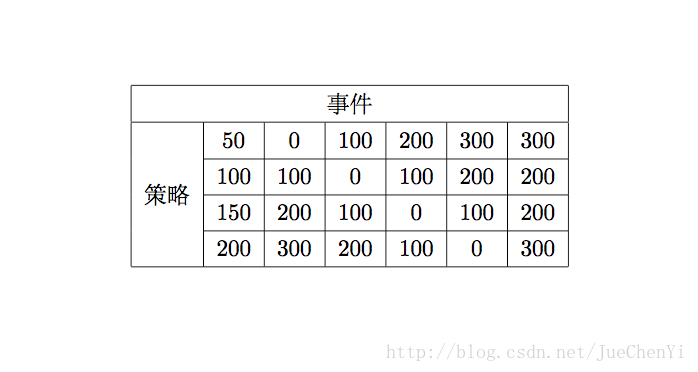
表格合并
\documentclass[UTF8]{ctexart}
%注意添加包
\usepackage{multirow}
\begin{document}
\begin{table}[!htbp]
\centering
\begin{tabular}{|c|c|c|c|c|c|c|} %表格7列 全部居中显示
\hline
\multicolumn{7}{|c|}{事件}\\ %横向合并7列单元格 两侧添加竖线
\hline
\multirow{4}*{策略}&50&0&100&200&300&300\\ %纵向合并4行单元格,*代表不确定{width}需要填什么,就将其替换为*
\cline{2-7} %为第二列到第七列添加横线
~&100&100&0&100&200&200\\ %~代表这个单元格啥也不填
\cline{2-7}
~&150&200&100&0&100&200\\
\cline{2-7}
~&200&300&200&100&0&300\\
\hline
\end{tabular}
\end{table}
\end{document}
vscode 设置
"latex-workshop.latex.tools": [
{
// 编译工具和命令
"name": "xelatex",
"command": "xelatex",
"args": [
"-synctex=1",
"-interaction=nonstopmode",
"-file-line-error",
"-pdf",
"%DOC%"
]
},
{
"name": "pdflatex",
"command": "pdflatex",
"args": [
"-synctex=1",
"-interaction=nonstopmode",
"-file-line-error",
"%DOC%"
]
},
{
"name": "bibtex",
"command": "bibtex",
"args": [
"%DOCFILE%"
]
}
],
"latex-workshop.latex.recipes": [
{
"name": "xelatex",
"tools": [
"xelatex"
]
},
{
"name": "xe->bib->xe->xe",
"tools": [
"xelatex",
"bibtex",
"xelatex",
"xelatex"
]
}
],
vscode操作
# paper 反选
ctrl+右键
pdf2eps
pdftops -eps [file].pdf
eps2pdf
epstopdf [file].eps
裁剪pdf文件
pdfcrop [file].pdf
编译tex文件
pdflatex test.tex
beamer
\documentclass{beamer}
\usepackage[utf8]{inputenc}
\usepackage{lmodern}
\usepackage{bookmark}
\usepackage{graphicx}
\usepackage{xeCJK} %导入中文包
\setCJKmainfont{SimHei} %中文字体采用黑体 Microsoft YaHei
\usetheme{Hannover}
\usecolortheme{spruce}
\tiny
\title{Graph Convolutional Network}
\author{josephlin}
\begin{document}
\frame{Graph Convolutional Network}
\section{Introduction}
\begin{frame}
\frametitle{CNN}
CNN中的卷积本质上就是利用一个共享参数的过滤器(kernel),通过计算中心像素点以及相邻像素点的加权和来构成feature map实现空间特征的提取,当然加权系数就是卷积核的权重系数。卷积核的系数通过是随机化初值,然后根据误差函数通过反向传播梯度下降进行迭代优化。\\
\includegraphics[height=4cm]{images/feature_map.jpg}
\end{frame}
\end{document}
避免eps文件存在Type3字体
使用eps2eps命令将图片的字体曲线化
eps2eps your.eps output.eps
# 查看pdf是否存在type3字体
pdffonts MY_PDF.pdf